![[CVPR 2024] Data Synthesis for Privacy](/generated/assets/images/posts/2024-05-28-cvpr2024.assets/thumbnail-800-bbdf19180.png)
Please open the link below to see the paper. Paper Link
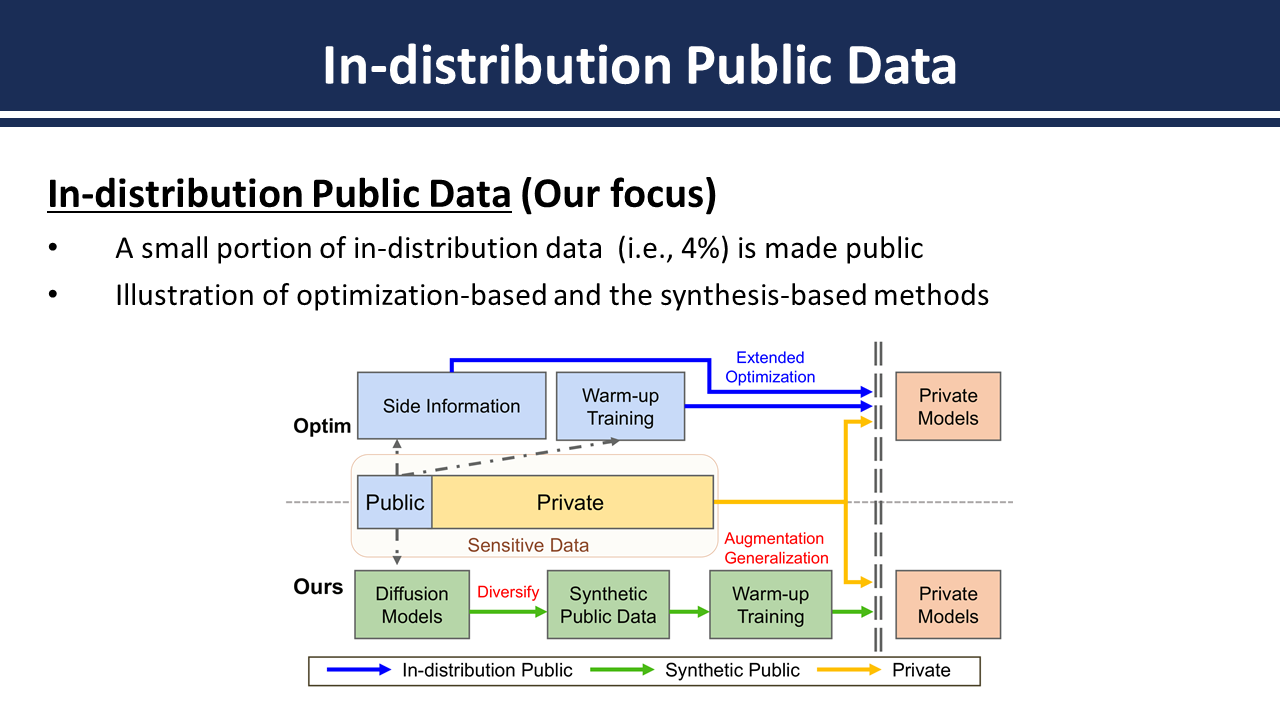
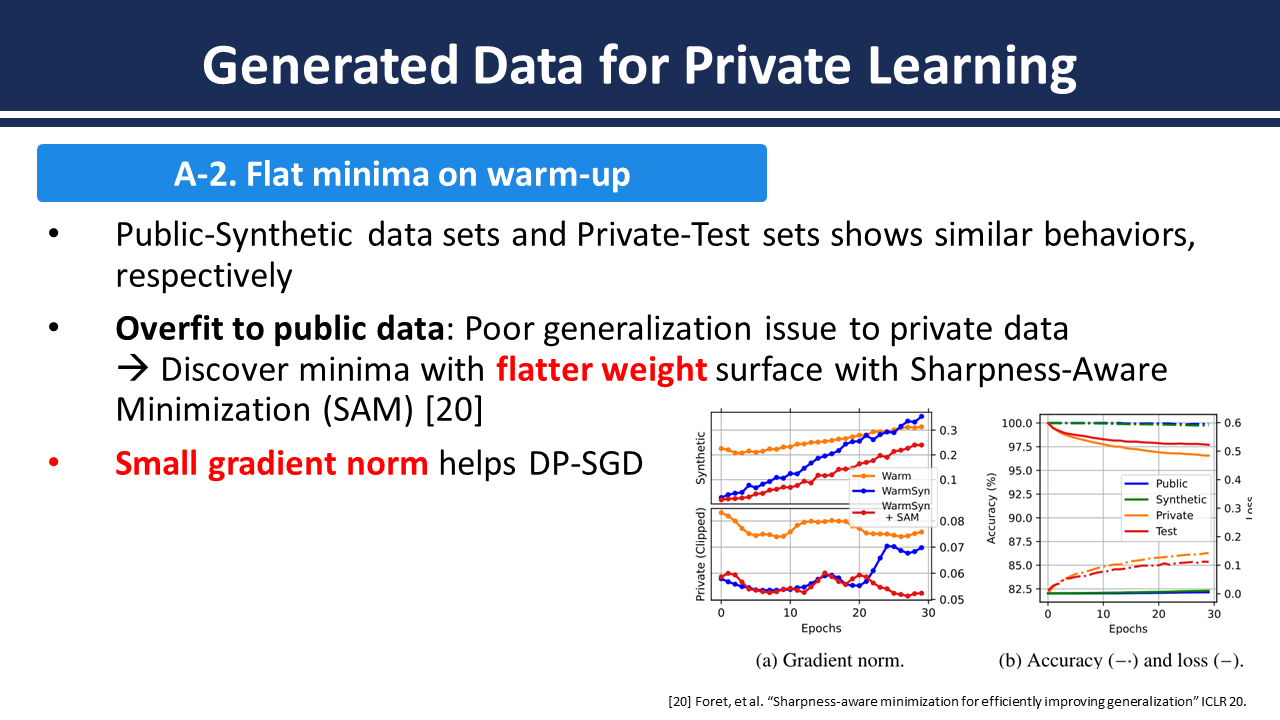
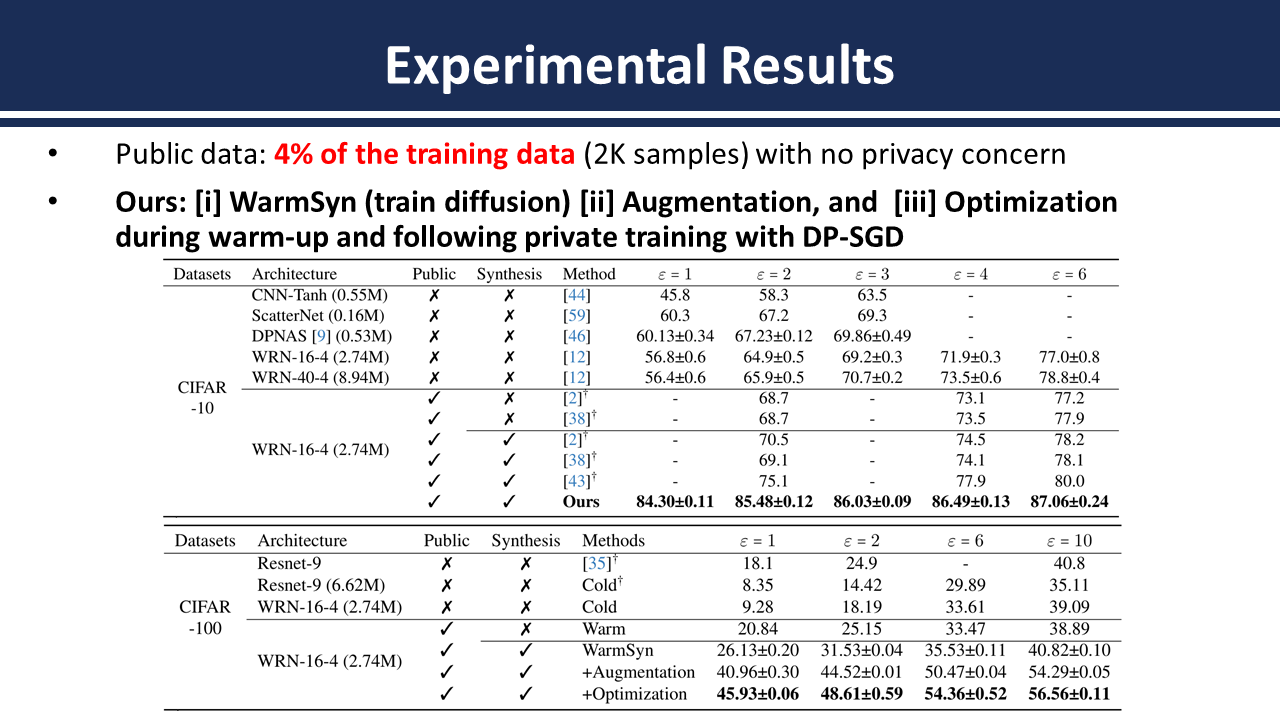
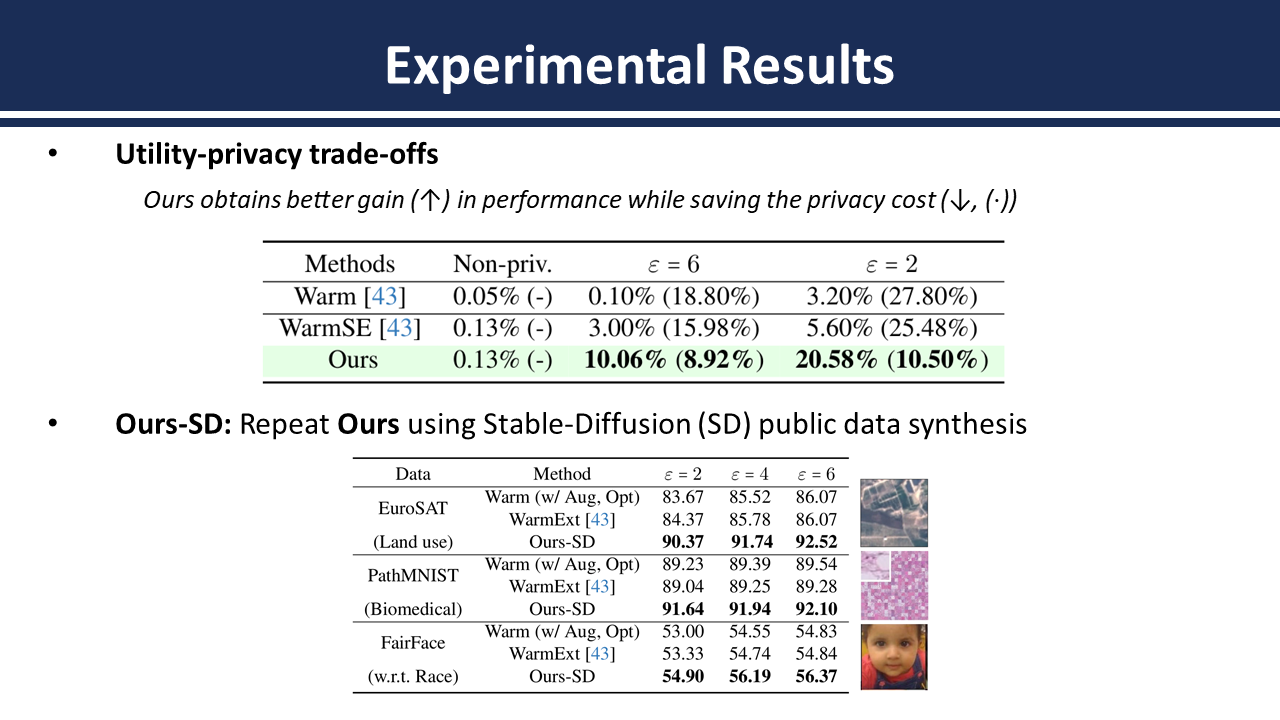
Abstract: To alleviate the utility degradation of deep learning image classification with differential privacy (DP) employing extra public data or pre-trained models has been widely explored. Recently the use of in-distribution public data has been investigated where tiny subsets of datasets are released publicly. In this paper we investigate a framework that leverages recent diffusion models to amplify the information of public data. Subsequently we identify data diversity and generalization gap between public and private data as critical factors addressing the limited public data. While assuming 4% of training data as public our method achieves 85.48% on CIFAR-10 with a privacy budget of ε=2 without employing extra public data for training.